


Introduction
We would like to introduce you to our latest open-source library: MAGDA. The name is an abbreviation for “Modular Asynchronous Graphs with Directed and Acyclic edges”, which fully describes the idea behind it. The library enables building modular data pipelines with asynchronous processing in e.g. machine learning and data science projects. It is dedicated for Python projects and is available on the NeuroSYS GitHub, as well as on the PyPI repository. It aids our R&D teams not only by introducing some abstraction (classes and functions) but also by imposing an architectural pattern onto the project.
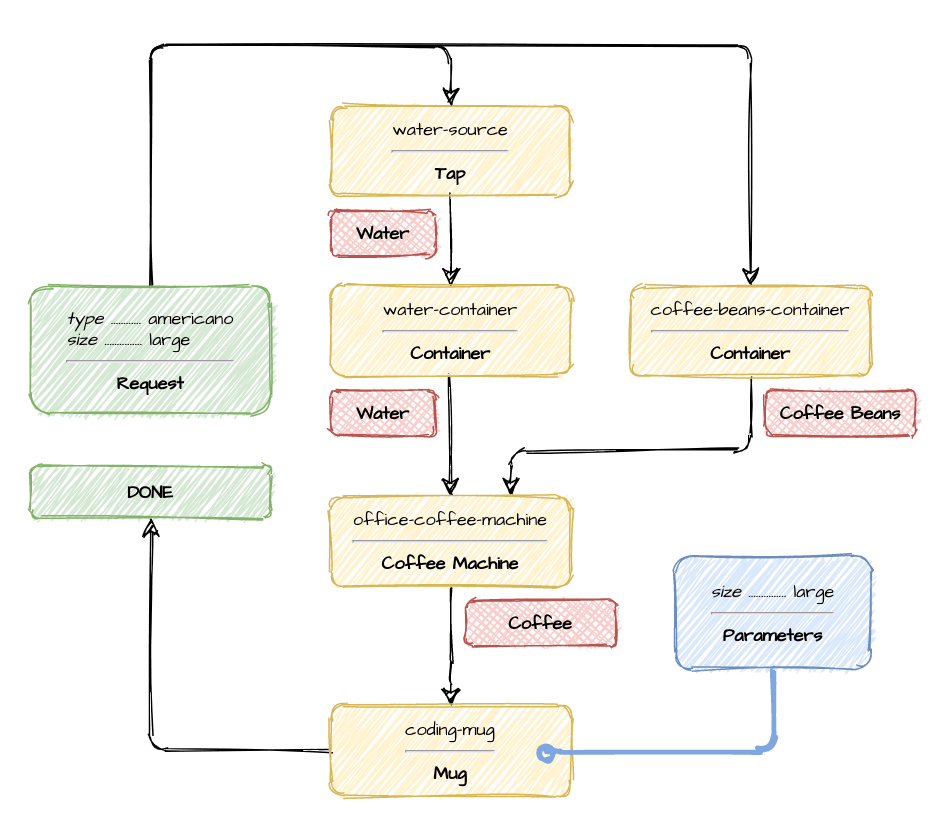 Example of coffee brewing pipeline with MAGDA
Example of coffee brewing pipeline with MAGDA
How does it get rid of spaghetti code?
As described above, MAGDA is composed of a few features:
1. Modular – code should be divided into small logical blocks (modules) with explicit input and output. The module could be a simple filter, database connector or a wrapper on a huge deep learning model. Just remember: one module – one role.
2. Asynchronous – the library is based on asyncio and ray, which allows it to run modules simultaneously. This gives us a simple optimization out of the box.
3. Graphs – modules are joined together into one connected pipeline/stream. During the design stage, we can think of modules as graph nodes and focus solely on their role and how they connect with each other.
4. Directed – the modules’ dependencies (and graph’s connections) are asymmetric. Since the graph always “flows” in the same direction, we can easily determine the ancestors and predecessors of a module. Therefore, we can clearly point out where the pipeline begins and ends.
5. Acyclic – each module is always processed just once during every run. This means that there is no path in the graph (modules’ dependencies) which starts and ends at the same module.
By combining all of these features, MAGDA creates a concrete project template, where each part of the project is enclosed into a module with a specific input and output. Each module’s behavior can also be modified by providing custom, module-specific parameters.
Application flow is created by joining modules into a pipeline, where each part of the pipeline can be replaced by another module with a corresponding interface. Finally, the whole pipeline can be easily written to and automatically loaded from a single YAML file.
When correctly applied, you obtain a project with clearly defined boundaries and interfaces. When modifying a module, you rely only on information provided by the accepted interfaces and parameters regardless of the rest of the system – similar to the “inversion of control” design pattern.
Use-cases
The library can be used in every Python project, which can be described as an instruction with a set of well-defined steps. Our R&D team is making use of MAGDA in various services: from small solutions with only a few modules to a complete Question-Answering pipeline. The most valuable is the easiness of replacing any part of the pipeline without concerning about the rest of the system. Creating a modular application is especially important when performing reliable and repeatable experiments, where only certain parts or parameters are modified. Apart from that, you can also gain from asynchronous processing of several subparts at the same time.
Summary
Since MAGDA is our brand new project (current version: 0.1), some features might still be missing. Feel free to create an issue, share a feature request, or post a question and contribute!
NeuroSYS GitHub: github.com/NeuroSYS-pl/magda
Documentation: github.com/NeuroSYS-pl/magda/wiki
PyPI Repository: pypi.org/project/magda